Platform
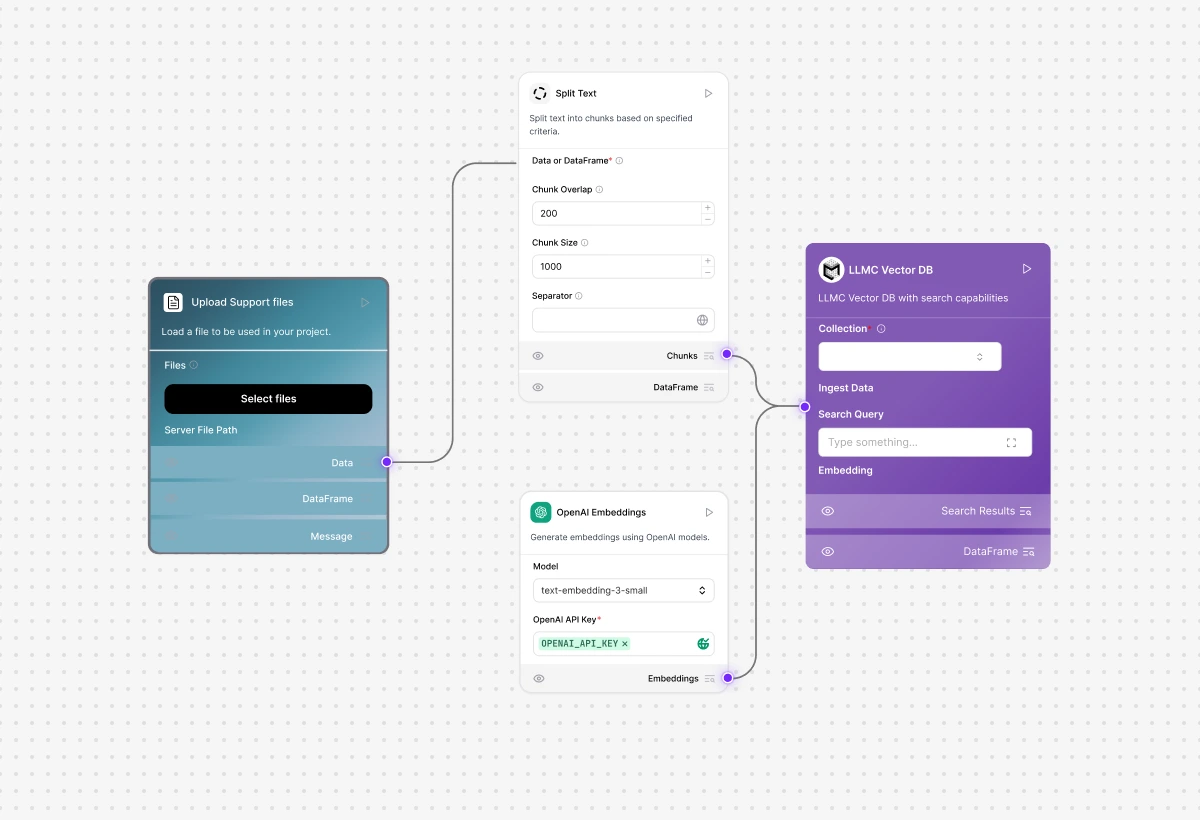
Built-In RAG Engine With Instant Indexing
Built-in vectorDB and retrieval engine, upload files, chunk, and index instantly for production-ready RAG applications without external database setup.
01
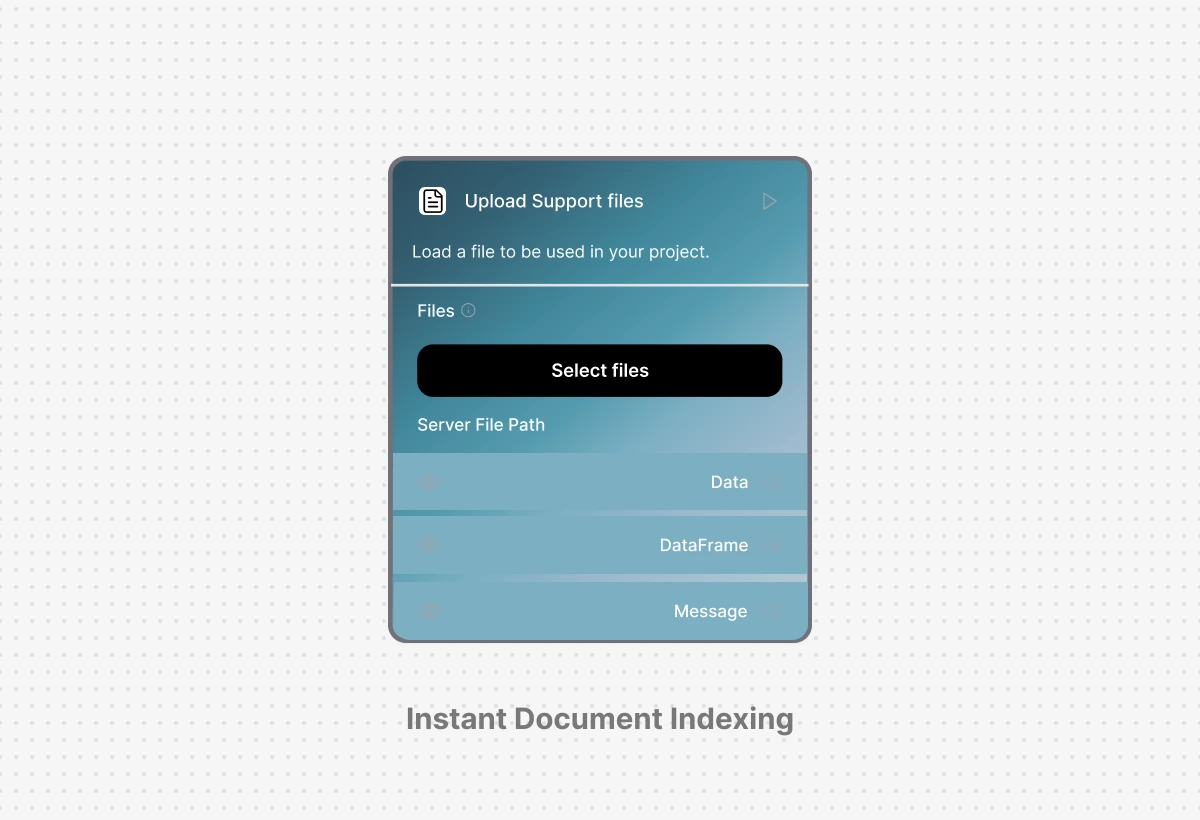
Instant Document Indexing: Upload and Query Immediately
Drag and drop PDFs, Word docs, or text files and start querying within seconds using automatic chunking and embedding generation. No manual preprocessing, no external vector database configuration, the native VectorDB handles everything from upload to retrieval with optimized defaults that work out of the box.
02
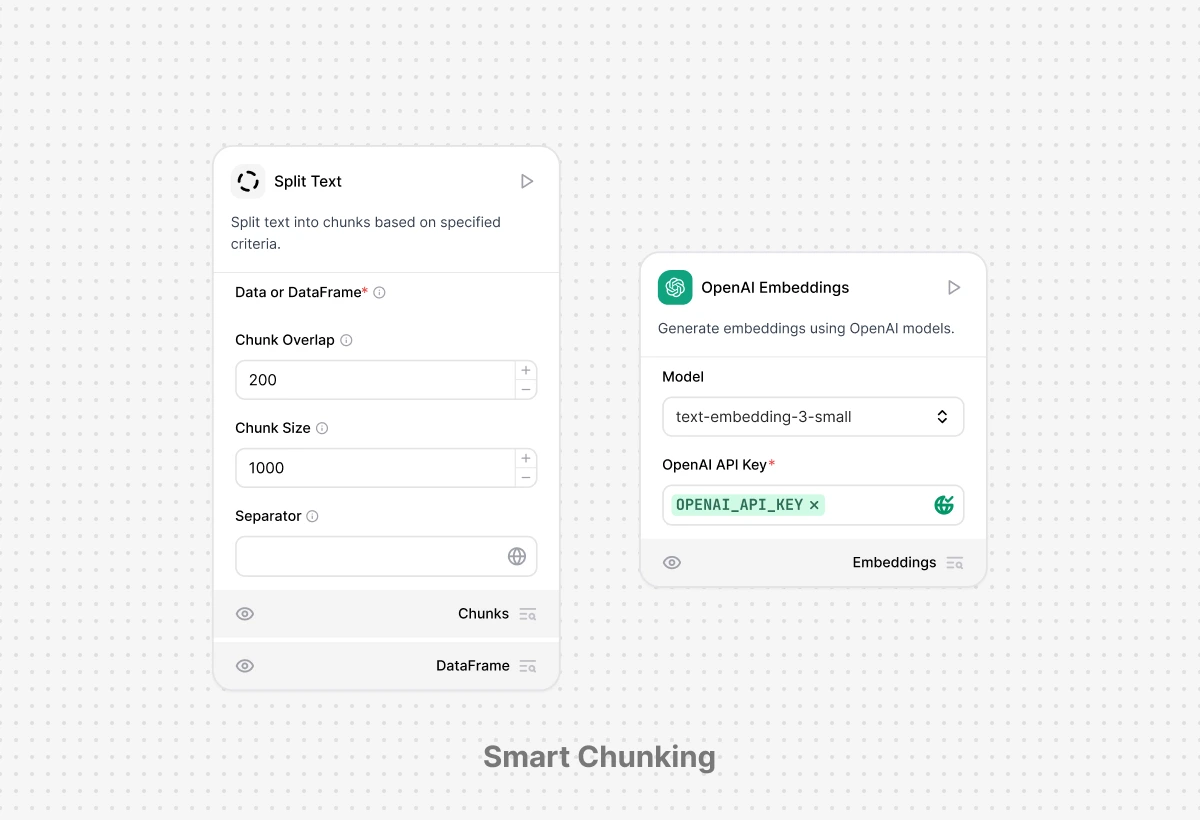
Smart Chunking & Embedding: Optimized Retrieval
Automatically split documents into semantically meaningful chunks using intelligent parsing that preserves context across paragraphs, tables, and headings to enable contextual retrieval for LLMs. Generate embeddings with your choice of models (OpenAI, Cohere, or custom) and store them in the built-in vector database, all configured with one click and optimized for accuracy and speed.
03
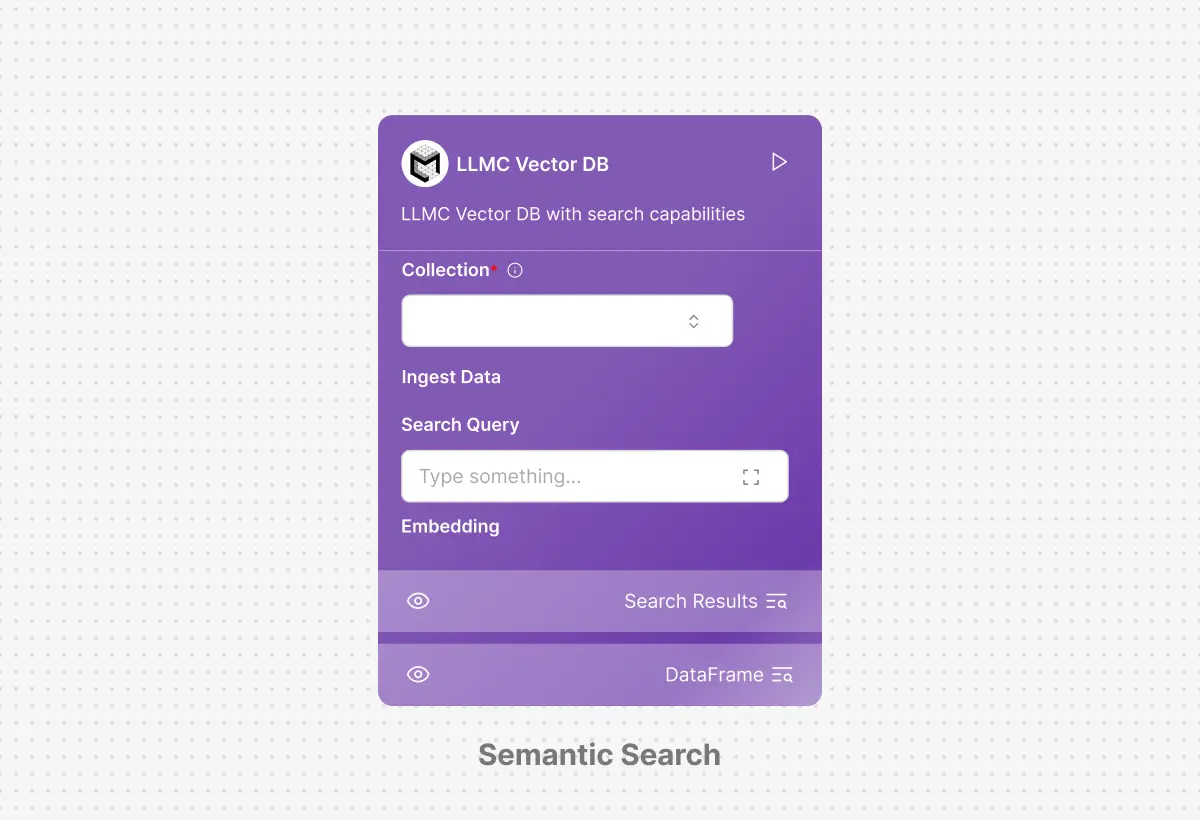
Semantic Search & Filtering: Context Aware Retrieval
Query your knowledge base using natural language and retrieve the most relevant chunks with hybrid search combining vector similarity and keyword matching. Apply metadata filters by document type, date, or custom tags to narrow results, ensuring your AI workflows pull accurate context every time without manual prompt engineering.
04
Version-Controlled Knowledge Base: Snapshot Your Data
Track every version of your document repository with automatic snapshots whenever files are added, updated, or removed. Roll back to previous states instantly if incorrect documents were indexed, compare knowledge base versions side-by-side, and maintain separate indexes for development and production environments with zero downtime.